Announcing pqR: A faster version of R
2013-06-22 at 2:32 pm 35 comments
pqR — a “pretty quick” version of R — is now available to be downloaded, built, and installed on Linux/Unix systems. This version of R is based on R-2.15.0, but with many performance improvements, as well as some bug fixes and new features. Notable improvements in pqR include:
- Multiple processor cores can automatically be used to perform some numerical computations in parallel with other numerical computations, and with the thread performing interpretive operations. No changes to R code are required to take advantage of such computation in “helper threads”.
- pqR makes a better attempt at avoiding unnecessary copying of objects, by maintaining a real count of “name” references, that can decrease when the object bound to a name changes. Further improvements in this scheme are expected in future versions of pqR.
- Some operations are avoided completely in pqR — for example, in pqR, the statement
for (i in 1:10000000) ...does not actually create a vector of 10000000 integers, but simply setsito each of these integers in turn.
There are also many detailed improvements in pqR that decrease general interpretive overhead or speed up particular operations.
I will be posting more soon about many of these improvements, and about the gain in performance obtained using pqR. For the moment, a quick idea of how much improvement pqR gives on simple operations can be obtained from the graph below (click to enlarge):
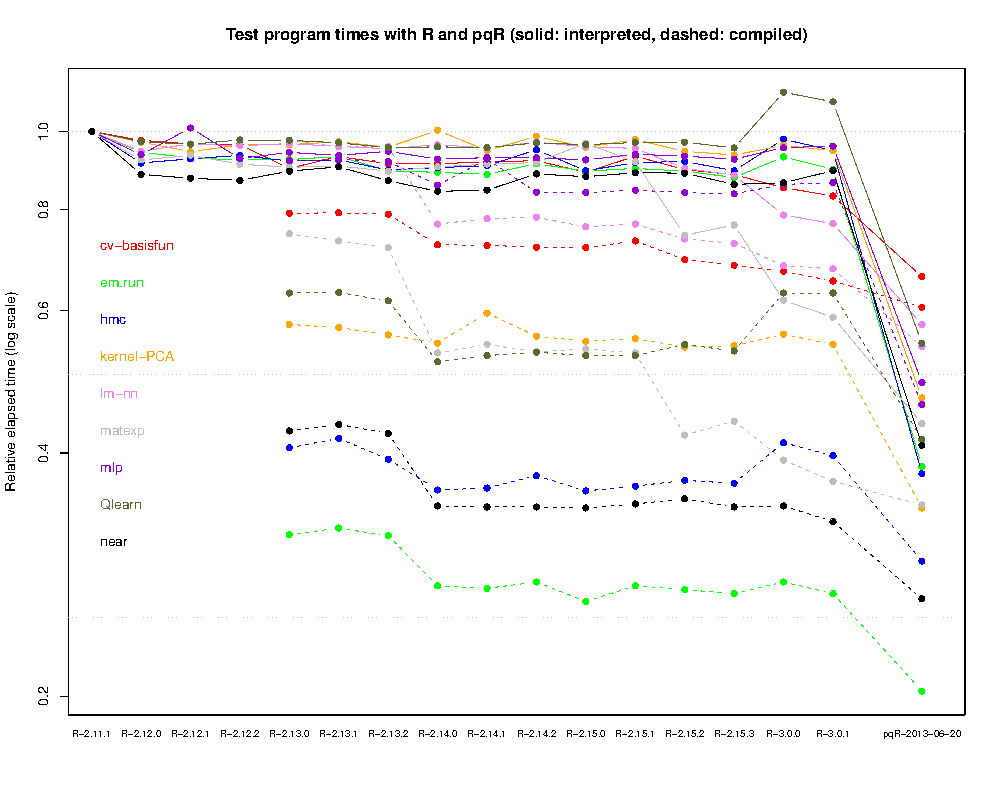
This shows the relative run times (on an Intel X5680 processor) of nine simple test programs (from the 2013-06-18 version of my R speed tests), using pqR, and using all releases of R by the R Core Team from 2.11.1 to 3.0.1. These programs mostly operate on small objects, doing simple operations, so this is a test of general interpretive overhead. A single thread was used for pqR (there is not much scope in these programs for parallelizing numeric computations).
As one can see, there has been little change in speed of interpreted programs since R-2.12.0, when some modifications that I proposed were incorporated into the R Core versions (and the R Core Team declined to incorporate many other modifications I suggested), though the speed of compiled programs has improved a bit since the compiler was introduced in R-2.13.0. The gain for interpreted programs from using pqR is almost as large as the gain from compilation. pqR also improves the speed of compiled programs, though the gain is less than for interpreted programs, with the result that the advantage of compilation has decreased in pqR. As I’ll discuss in future posts, for some operations, pqR is substantially faster when the compiler is not used. In particular, parallel computation in helper threads does not occur for operations started from compiled R code.
For some operations, the speed-up from using pqR is much larger than seen in the graph above. For example, vector-matrix multiplies are over ten times faster in pqR than in R-2.15.0 or R-3.0.1 (see here for the main reason why, though pqR solves the problem differently than suggested there).
The speed improvement from using pqR will therefore vary considerably from one R program to another. I encourage readers who are comfortable installing R from source on a Unix/Linux system to try it out, and let me know what performance improvements (and of course bugs) you find for your programs. You can leave a comment on this post, or mail me at radfordneal@gmail.com.
You can get pqR here, where you can also find links to the source repository, a place to report bugs and other issues, and a wiki that lists systems where pqR has been tested, plus a few packages known to have problems with pqR. As of now, pqR has not been tested on Windows and Mac systems, and compiled versions for those systems are not available, but I hope they will be fairly soon.
UPDATE: You can read more about pqR in my posts on parallel computation with helper threads in pqR, comparing the speed of pqR with R-2.15.0 and R-3.0.1, how pqR makes programs faster by not doing things, and fixing R’s NAMED problems in pqR.
Entry filed under: Computing, R Programming, Statistics, Statistics - Computing. Tags: pqR.
35 Comments Add your own
Leave a comment
Trackback this post | Subscribe to the comments via RSS Feed

1. Vignesh | 2013-06-23 at 2:41 am
Reblogged this on R Dairy and commented:
Great innovation on R by Radford Neal
2. Erick Staal | 2013-06-23 at 5:09 am
Why the fork?
3. Johan Rex | 2013-06-23 at 5:16 am
Why have you chosen to create your own fork of R instead of contributing your changes to the main R distribution?
4. Radford Neal | 2013-06-23 at 8:42 am
You should address that question to the R Core Team.
5. Robert | 2013-06-23 at 9:09 am
Did you try to contribute to R distribution but you met resistance by R Core Team?
6. Radford Neal | 2013-06-23 at 9:36 am
I don’t intend to comment on this question further, but if you’re interested you can search the r-devel archives back to August 2010 and look at the R Core Team’s bug reporting repository for some history.
7. Soumendra | 2013-06-23 at 9:35 am
Are people not reading the post?!!! Neal says very clearly he a lot of his changes were not accepted by R team and (hence) pqR was born.
Personally, I would like to see pqR for R 3.x. One in the pipeline?
8. Me | 2013-06-23 at 11:27 am
Very cool. Agree with the suggestion in relation to version 3, but would also be fantastic to see a benchmark against Revolution and Julia.
9. Jason | 2013-06-23 at 4:54 pm
This is quite exciting. A comparison of some production code gave a 4 times speed improvement pqR.
10. Parallel computation with helper threads in pqR | Radford Neal's blog | 2013-06-23 at 5:00 pm
[…] innovative feature of pqR (my new, faster, version of R), is that it can perform some numeric computations in […]
11. A faster R? | ecology & stats | 2013-06-23 at 6:33 pm
[…] on ways to make it more efficient. He’s reached a bit of milestone in the last few days, with the release of pqR. Check it out…it looks really […]
12. Koma | 2013-06-23 at 7:05 pm
Very intrigued with pqR. I wonder if this would make something like a Raspberry Pi somewhat decent to pair with R now?
13. Radford Neal | 2013-06-23 at 7:30 pm
Well, as mentioned in the pqR wiki, pqR does seem to work on the Raspberry Pi (model B, with Raspian Linux), unlike R-2.15.0, which sort-of-works, but fails with functions like “sub”. And on those speed tests where R-2.15.0 works, pqR shows speed-ups over R-2.15.0 similar to those on other machines (eg, 2.8 times faster on my simple EM test program, not compiled). This should certainly help with not-too-challenging data analysis tasks.
However, this still makes pqR on the Raspberry Pi about 33 times slower than on a high-end Intel processor (using only one core), which is only a bit better than the factor of 41 for R-2.15.0, so I don’t think it turns the Pi into a great R engine…
14. koma | 2013-06-23 at 9:54 pm
Thanks for the quick reply and reality check… haha. I am trying to figure out a portable R solution. I would like to use a terminal to access R on an iPad Mini + keyboard as I ride the bus, and I do not enjoy lugging a laptop around… Perhaps, I will check back on the pqR when the Parallella from Adapteva is released (for reference: http://www.adapteva.com)
15. Posterior samples | Sam Clifford | 2013-06-23 at 8:00 pm
[…] Neal has just announced pqR, “pretty quick R”, which is designed to make use of multiple cores wherever possible […]
16. Oren | 2013-06-24 at 5:46 am
Well, pqR seems to work well for me. Installation was easier than I thought it would be, and pqR is about 50% faster than R 2.14.1 on my machine (running stochasitc simulations of epidemics). The results look pretty much the same.
I wish it was released two or three years earlier :D
Brilliant name, by the way.
17. Christopher Aden | 2013-06-24 at 11:23 am
Hi Radford,
You’re the statistics equivalent of a rockstar for those in the know! I wanted to address one of the final notes you made: “As of now, pqR has not been tested on Windows and Mac systems, and compiled versions for those systems are not available, but I hope they will be fairly soon.”
I can confirm that pqR works on Mac, with some minor caveats: XCode’s version of GCC will not compile pqR–it is missing thread-local variable support, which is needed for OpenMP. The solution to this is either to install GCC from source from the FSF, or grab a copy from Homebrew/Fink/MacPorts. The FSF’s GCC has the thread support pqR needs. Point pqR to the new C compiler and make sure you’re using a 64bit version of gfortran during the configure step, and the rest went fine for me.
Keep up the great work,
Christopher
18. Jan de Leeuw | 2013-06-24 at 1:42 pm
Compiles/runs fine on Mavericks (OS X 10.9, darwin 13) using clang/clang++ (no OpenMP) and gfortran from home-brew. Just replace
/#include
with
#include
in vecLibg95c.c
19. Julius | 2013-06-24 at 2:57 pm
no windows version yet? Nice work.
20. Comparing the speed of pqR with R-2.15.0 and R-3.0.1 | Radford Neal's blog | 2013-06-24 at 11:40 pm
[…] tests for R. Some of these tests were used to show how pqR speeds up simple real programs in my post announcing pqR, and to show the speed-up obtained with helper threads in pqR on systems with multiple processor […]
21. Azo | 2013-06-25 at 12:56 am
Hopefully someone can post binaries for various systems (Mac OS X notably)!
22. a | 2013-06-25 at 2:07 pm
Also of note is riposte:
Click to access pact080talbot.pdf
23. datanalytics » pqR: un R más rápido | 2013-06-26 at 12:39 pm
[…] no mucho, Radford Neal publicó pqR, una versión de R más rápida. Y algunos os preguntaréis qué es y de dónde salió esa […]
24. Eine schnellere Version von R? - Volker Hatz | 2013-06-30 at 2:22 pm
[…] Vergleichender Benchmark […]
25. R by Radford Neal | Images of Yeast | 2013-07-05 at 5:50 pm
[…] won’t repeat any more of the the post announcing it, check it out for yourself. I hate to be a back-seat developer, but why not use the name […]
26. Randy Zwitch (@randyzwitch) | 2013-07-05 at 9:52 pm
Since pqR is a fork of R, does that mean it works with RStudio?
27. Radford Neal | 2013-07-05 at 10:06 pm
Yes, it works with RStudio, if you use the latest version (2013-06-28). You need to configure it with the –enable-R-shlib option (same as is necessary for R-2.15.0).
You will also need to tell RStudio to use pqR, rather than your currently installed R (assuming you didn’t replace that with pqR). You can do this by setting the RSTUDIO_WHICH_R environment variable to …/bin/R, where … is the directory you made pqR in, as explained at http://www.rstudio.com/ide/docs/advanced/versions_of_r
28. Hyndsight - Reflections on UseR! 2013 | 2013-07-12 at 6:02 pm
[…] future releases will include the bug fixes and performance enhancements identified by Radford Neal. In question time, Duncan explained why we will probably never have packages dependent […]
29. Longhai Li | 2013-07-15 at 1:25 am
The work is really terrific. Thanks for the work. I am thinking that maybe you could start another development of program like R from S years ago. How about naming it Q directly, to distinguish from R, meaning more advanced (or newer than R), just like from S to R.
30. Yan | 2013-07-17 at 11:38 am
Does anyone compiled pqR for Windows 7?
Many thanks! I have 32 cores on my machine so I would like to use them at their best!
Yan
31. Radford Neal | 2013-07-17 at 11:53 am
Some people have tried using it on Windows, and after some tweaking succeeded, both with and without helper threads, but I don’t recommend this until I’ve put in all the required tweaks and tested them myself.
Note that pqR won’t necessarily use all 32 cores! It’s limited by how many parallel operations show up in your R code. At present, pqR doesn’t try to do a single operation with more than one core. For example, A = B%*%C + D%*%E will (assuming enough cores, helpers are enabled, etc.) do the two matrix multiplies and the add in parallel, but each individual operation will be done with a single core (so three cores will be used in total). Though actually, it’s possible you could get the matrix multiplies to each be done with multiple cores, if you used a muliti-threaded BLAS, but that wouldn’t be due to changes in pqR.
32. Tomas | 2013-07-23 at 3:43 am
Great work!. What about big data? Does pqR have the same memory limitations that R has? If you just make a fork of R, It will be great to have it working efficiently with big data using all the existing libraries without the need to make any change on the code.
33. Radford Neal | 2013-07-23 at 8:21 am
It currently has the same object size limitations at R-2.15.0, but ought to work better with large objects because it won’t make copies of them as often as R-2.15.0 does (and R-3.0.1 still does).
At some point, pqR may support objects with more that 2 billion elements, which are supported (with some limitations) in R-3.0.x, but not yet.
34. Fun With Just-In-Time Compiling: Julia, Python, R and pqR | 2013-09-02 at 7:57 pm
[…] Euler problems using Julia, Python, Python with Numba, PyPy, R, R using the compiler package, pqR and pqR using the compiler package. Here’s what I […]
35. Fun With Just-In-Time Compiling: Julia, Python, R and pqR | juliabloggers.com | 2014-06-16 at 8:39 am
[…] Euler problems using Julia, Python, Python with Numba, PyPy, R, R using the compiler package, pqR and pqR using the compiler package. Here’s what I […]