Posts tagged ‘pqR’
New release of pqR — faster, and now compatible with R-2.15.1
 |
I have released a new version of my “pretty quick” R interpreter, pqR-2016-10-05.
One major change with this version is that pqR, which was based on R-2.15.0, is now compatible with R-2.15.1. This allows for an increased number of packages in the pqR repository. |
This release also has some significant speed improvements, a new form of the “for” statement, for conveniently iterating across columns or down rows of a matrix, and a new, less error-prone way for C functions to “protect” objects from garbage collection. There are also a few bug fixes (including fixes for some bugs that are also in the current R core release).
You can read more in the NEWS file, and get it from pqR-project.org.
Currently, pqR is distributed in source form only, and so you need to be comfortable compiling it yourself. It has been tested on Linux/Unix systems (with Intel/AMD, ARM, PowerPC, and SPARC processors), on Mac OS X (including macOS Sierra), and on Microsoft Windows (XP, 7, 8, 10) systems.
I plan to soon put up posts with more details on some of the features of this and the previous pqR release, as well as a post describing some of my future plans for pqR.
Deferred evaluation in Renjin, Riposte, and pqR
The previously sleepy world of R implementation is waking up. Shortly after I announced pqR, my “pretty quick” implementation of R, the Renjin implementation was announced at UserR! 2013. Work also proceeds on Riposte, with release planned for a year from now. These three implementations differ greatly in some respects, but interestingly they all try to use multiple processor cores, and they all use some form of deferred evaluation.
Deferred evaluation isn’t the same as “lazy evaluation” (which is how R handles function arguments). Deferred evaluation is purely an implementation technique, invisible to the user, apart from its effect on performance. The idea is to sometimes not do an operation immediately, but instead wait, hoping that later events will allow the operation to be done faster, perhaps because a processor core becomes available for doing it in another thread, or perhaps because it turns out that it can be combined with a later operation, and both done at once.
Below, I’ll sketch how deferred evaluation is implemented and used in these three new R implementations, and also comment a bit on their other characteristics. I’ll then consider whether these implementations might be able to borrow ideas from each other to further expand the usefulness of deferred evaluaton. (more…)
Fixing R’s NAMED problems in pqR
In R, objects of most types are supposed to be treated as “values”, that do not change when other objects change. For instance, after doing the following:
a <- c(1,2,3) b <- a a[2] <- 0
b[2] is supposed to have the value 2, not 0. Similarly, a vector passed as an argument to a function is not normally changed by the function. For example, with b as above, calling f(b), will not change b even if the definition of f is f <- function (x) x[2] <- 0.
This semantics would be easy to implement by simply copying an object whenever it is assigned, or evaluated as the argument to a function. Unfortunately, this would be unacceptably slow. Think, for example, of passing a 10000 by 10000 matrix as an argument to a little function that just accesses a few elements of the matrix and returns a value computed from them. The copying would take far longer than the computation within the function, and the extra 800 Megabytes of memory required might also be a problem.
So R doesn’t copy all the time. Instead, it maintains a count, called NAMED, of how many “names” refer to an object, and copies only when an object that needs to be modified is also referred to by another name. Unfortunately, however, this scheme works rather poorly. Many unnecessary copies are still made, while many bugs have arisen in which copies aren’t made when necessary. I’ll talk about this more below, and discuss how pqR has made a start at solving these problems. (more…)
How pqR makes programs faster by not doing things
One way my faster version of R, called pqR (see updated release of 2013-06-28), can speed up R programs is by not even doing some operations. This happens in statements like for (i in 1:1000000) ..., in subscripting expressions like v[i:1000], and in logical expressions like any(v>0) or all(is.na(X)).
This is done using pqR’s internal “variant result” mechanism, which is also crucial to how helper threads are implemented. This mechanism is not visible to the user, apart from the reductions in run time and memory usage, but knowing about it will make it easier to understand the performance of programs running under pqR. (more…)
Comparing the speed of pqR with R-2.15.0 and R-3.0.1
As part of developing pqR, I wrote a suite of speed tests for R. Some of these tests were used to show how pqR speeds up simple real programs in my post announcing pqR, and to show the speed-up obtained with helper threads in pqR on systems with multiple processor cores.
However, most tests in the suite are designed to measure the speed of more specific operations. These tests provide insight into how much various modifications in pqR have improved speed, compared to R-2.15.0 on which it was based, or to the current R Core release, R-3.0.1. These tests may also be useful in judging how much you would expect your favourite R program to be sped up using pqR, based on what sort of operations the program does.
Below, I’ll present the results of these tests, discuss a bit what some of the tests are doing, and explain some of the run time differences. I’ll also look at the effect of “byte-code” compilation, in both pqR and the R Core versions of R. (more…)
Parallel computation with helper threads in pqR
One innovative feature of pqR (my new, faster, version of R), is that it can perform some numeric computations in “helper” threads, in parallel with other such numeric computations, and with interpretive operations performed in the “master” thread. This can potentially speed up your computations by a factor as large as the number of processor cores your system has, with no change to your R programs. Of course, this is a best-case scenario — you may see little or no speed improvement if your R program operates only on small objects, or is structured in a way that inhibits pqR from scheduling computations in parallel. Below, I’ll explain a bit about helper threads, and illustrate when they do and do not produce good speed ups. (more…)
Announcing pqR: A faster version of R
pqR — a “pretty quick” version of R — is now available to be downloaded, built, and installed on Linux/Unix systems. This version of R is based on R-2.15.0, but with many performance improvements, as well as some bug fixes and new features. Notable improvements in pqR include:
- Multiple processor cores can automatically be used to perform some numerical computations in parallel with other numerical computations, and with the thread performing interpretive operations. No changes to R code are required to take advantage of such computation in “helper threads”.
- pqR makes a better attempt at avoiding unnecessary copying of objects, by maintaining a real count of “name” references, that can decrease when the object bound to a name changes. Further improvements in this scheme are expected in future versions of pqR.
- Some operations are avoided completely in pqR — for example, in pqR, the statement
for (i in 1:10000000) ...does not actually create a vector of 10000000 integers, but simply setsito each of these integers in turn.
There are also many detailed improvements in pqR that decrease general interpretive overhead or speed up particular operations.
I will be posting more soon about many of these improvements, and about the gain in performance obtained using pqR. For the moment, a quick idea of how much improvement pqR gives on simple operations can be obtained from the graph below (click to enlarge):
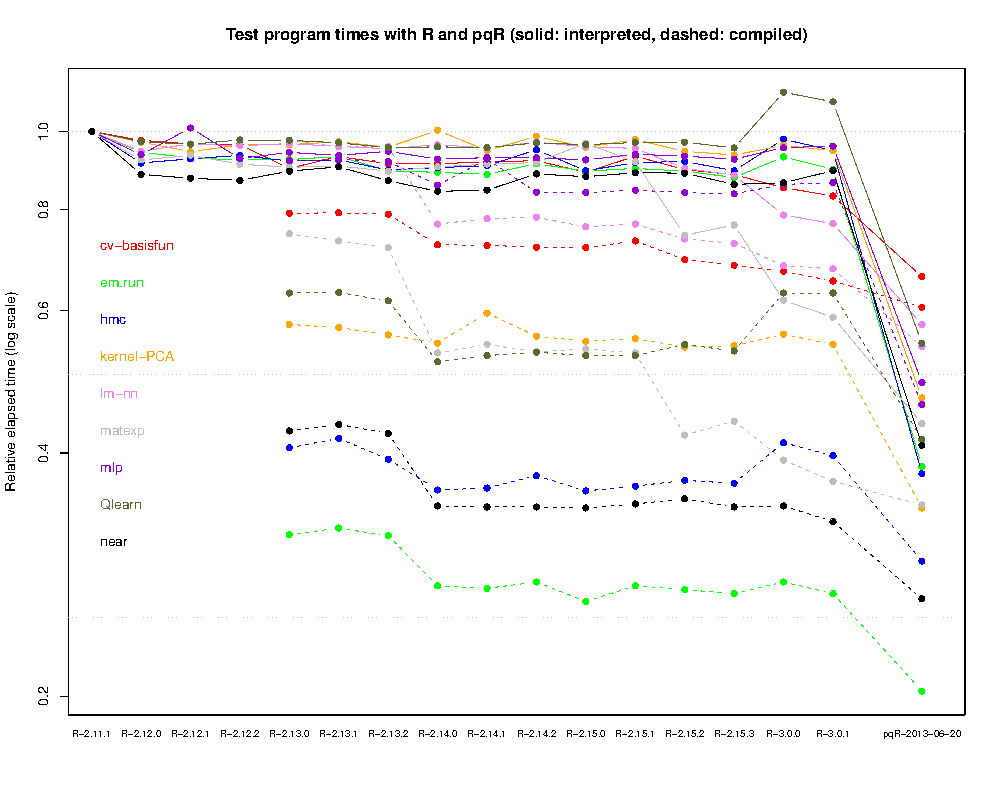
This shows the relative run times (on an Intel X5680 processor) of nine simple test programs (from the 2013-06-18 version of my R speed tests), using pqR, and using all releases of R by the R Core Team from 2.11.1 to 3.0.1. These programs mostly operate on small objects, doing simple operations, so this is a test of general interpretive overhead. A single thread was used for pqR (there is not much scope in these programs for parallelizing numeric computations).
As one can see, there has been little change in speed of interpreted programs since R-2.12.0, when some modifications that I proposed were incorporated into the R Core versions (and the R Core Team declined to incorporate many other modifications I suggested), though the speed of compiled programs has improved a bit since the compiler was introduced in R-2.13.0. The gain for interpreted programs from using pqR is almost as large as the gain from compilation. pqR also improves the speed of compiled programs, though the gain is less than for interpreted programs, with the result that the advantage of compilation has decreased in pqR. As I’ll discuss in future posts, for some operations, pqR is substantially faster when the compiler is not used. In particular, parallel computation in helper threads does not occur for operations started from compiled R code.
For some operations, the speed-up from using pqR is much larger than seen in the graph above. For example, vector-matrix multiplies are over ten times faster in pqR than in R-2.15.0 or R-3.0.1 (see here for the main reason why, though pqR solves the problem differently than suggested there).
The speed improvement from using pqR will therefore vary considerably from one R program to another. I encourage readers who are comfortable installing R from source on a Unix/Linux system to try it out, and let me know what performance improvements (and of course bugs) you find for your programs. You can leave a comment on this post, or mail me at radfordneal@gmail.com.
You can get pqR here, where you can also find links to the source repository, a place to report bugs and other issues, and a wiki that lists systems where pqR has been tested, plus a few packages known to have problems with pqR. As of now, pqR has not been tested on Windows and Mac systems, and compiled versions for those systems are not available, but I hope they will be fairly soon.
UPDATE: You can read more about pqR in my posts on parallel computation with helper threads in pqR, comparing the speed of pqR with R-2.15.0 and R-3.0.1, how pqR makes programs faster by not doing things, and fixing R’s NAMED problems in pqR.
