The Harmonic Mean of the Likelihood: Worst Monte Carlo Method Ever
2008-08-17 at 12:09 am 38 comments
Many Bayesian statisticians decide which of several models is most appropriate for a given dataset by computing the marginal likelihood of each model (also called the integrated likelihood or the evidence). The marginal likelihood is the probability that the model gives to the observed data, averaging over values of its parameters with respect to their prior distribution. If x is the entire dataset and t is the entire set of parameters, then the marginal likelihood is

Here, I use P(x) and so forth to represent a probability density or mass function, as appropriate. After P(x) has been computed for all models (which may well have different sorts of parameters), the model with largest marginal likelihood is chosen, or more elaborately, predictions might be made by averaging over all models, with weights proportional to their marginal likelihoods (perhaps multiplied by a prior factor for each model).
Use of the marginal likelihood to evaluate models is often rather dubious, because it is very sensitive to any flaws in the specifications of the priors for the parameters of each model. That may be a topic for a future post, but I’ll ignore that issue here, and talk instead about how people try to compute the marginal likelihood.
Computing P(x) is difficult, because it’s an integral of what is usually a highly variable function over what is typically a high dimensional parameter space. Of course, for some models the integral is analytically tractable (typically ones with conjugate priors), and if the parameter space is low-dimensional, brute-force numerical integration may work. For most interesting models, however, the only known way of accurately computing P(x) is by applying quite sophisticated Monte Carlo techniques, which have long been researched by physicists in order to solve the essentially identical problem of computing “free energies”. See, for example, Section 6.2 of my review of Probabilistic Inference Using Markov Chain Monte Carlo Methods, and my paper on Annealed Importance Sampling.
These sophisticated techniques aren’t too well-known, however. They also take substantial effort to implement and substantial amounts of computer time. So it’s maybe not surprising that many people have been tempted by what seems like a much easier method — compute the harmonic mean of the likelihood with respect to the posterior distribution, using the same Markov Chain Monte Carlo (MCMC) runs that they have usually already done to estimate parameters or make predictions based on each model.
The method is very simple. You obtain a sample of points from the posterior distribution of the model given the observed data, probably using MCMC. For each such point, you compute the reciprocal of the likelihood, average these reciprocal likelihood values, and then take the reciprocal of the average as an estimate of the marginal likelihood of the model. That is, given a sample t1, …, tn from the posterior distribution, the marginal likelihood is estimated by
![P(x) \ \approx\ 1 \, \big/ \, \big[ (1/n) \sum\limits_{i=1}^n 1/P(x|t_i) \big]](https://s0.wp.com/latex.php?latex=P%28x%29+%5C+%5Capprox%5C+1+%5C%2C+%5Cbig%2F+%5C%2C+%5Cbig%5B+%281%2Fn%29+%5Csum%5Climits_%7Bi%3D1%7D%5En+1%2FP%28x%7Ct_i%29+%5Cbig%5D+&bg=ffffff&fg=414141&s=-1&c=20201002)
The good news is that the Law of Large Numbers guarantees that this estimator is consistent — ie, it will very likely be very close to the correct answer if you use a sufficiently large number of points from the posterior distribution. To see this, note that the expectation of what is averaged is
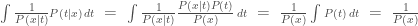
The bad news is that the number of points required for this estimator to get close to the right answer will often be greater than the number of atoms in the observable universe. The even worse news is that it’s easy for people to not realize this, and to naively accept estimates that are nowhere close to the correct value of the marginal likelihood.
It’s easy to see why this estimator can’t possibly work well in practice. As is well-known, the posterior distribution for a Bayesian model is often much narrower than the prior, and it is often not very sensitive to what the prior is, as long as the prior is broad enough to encompass the region with high likelihood. Suppose this is so for a model with 50 parameters, each with a N(0,1) prior, independent of the others. If the data is quite informative, producing a narrow posterior distribution, and the true values of the parameters are in the range [-1,+1], it’s likely that the posterior distribution would be virtually identical if the priors were changed to N(0,102). Since the prior affects the harmonic mean estimate of the marginal likelihood only through its effect on the posterior distribution, it follows that the harmonic mean estimate is very likely to be virtually the same for the two priors, for any reasonable size sample from the posterior. However, the actual value of the marginal likelihood will be approximately 1050 times smaller for the model with N(0,102) priors, since for each of the 50 parameters, the prior probability of a value that matches the data will be ten times smaller for a N(0,102) prior than for a N(0,1) prior. The harmonic mean method is clearly hopelessly inaccurate.
But many people use it anyway! They’ve probably heard that the harmonic mean estimator often has infinite variance, which even the papers advocating it usually mention. But then they’ve also heard that it’s possible for MCMC methods to fail to converge in any reasonable time. They may see these as analogous worries, and think that one can’t let such worries get in the way of actually doing something. This fails to account for how utterly horrible the harmonic mean estimator actually is.
Consider the following example, which is simple enough that the exact marginal likelihood can easily be calculated, but is otherwise typical of real problems. Let x be a single real data point, with N(t,s12) distribution, and let the prior distribution for the parameter t be N(0,s02). It’s easy to see that the marginal distribution of x is N(0,s02+s12). Standard results say that the posterior distribution of t given x is normal, with its precision (reciprocal of variance) being the sum of the data precision and prior precision, and its mean being the weighted average of the data and the prior mean, with weights proportional to the corresponding precisions — ie, in this model, the posterior distribution for t given x is N((x/s12)/(s0-2+s1-2), 1/(s0-2+s1-2)). We can easily sample from this posterior distribution without having to use MCMC.
I’ve written some functions (in the R language) for testing the harmonic mean method for this example. Here’s the function for finding the harmonic mean estimate:
harmonic.mean.marg.lik <- function (x, s0, s1, n)
{ post.prec <- 1/s0^2 + 1/s1^2
t <- rnorm(n,(x/s1^2)/post.prec,sqrt(1/post.prec))
lik <- dnorm(x,t,s1)
1/mean(1/lik)
}
The arguments of this function are the observed data, x, the values of the hyperparameters, s0 and s1, and the sample size for the harmonic mean estimate. Here’s what we get using this function to estimate the marginal likelihood when the hyperparameters are s0=10 and s1=1, the observed data is x=2, and a sample of 10 million points from the posterior distribution is used for the estimate:
> set.seed(1); > for (i in 1:5) + print(harmonic.mean.marg.lik(2,10,1,10^7)) [1] 0.08439447 [1] 0.0989342 [1] 0.0973829 [1] 0.08654892 [1] 0.09364961
The estimation is done five times, so we can better see the properties of the harmonic mean estimator for this problem. There is some variation in the estimates, but clearly the true value of the marginal likelihood is likely to be in the interval (0.08,0.10), right?
No, actually. Here’s the true value, found with another function from the above file:
> true.marg.lik(2,10,1) [1] 0.03891791
This is a pretty big error. We can make the error even bigger by just increasing the prior standard deviation to s0=1000:
> set.seed(1) > harmonic.mean.marg.lik(2,1000,1,10^7) [1] 0.0791889 > true.marg.lik(2,1000,1) [1] 0.0003989413
As expected from the argument above, the harmonic mean estimate is not much affected by the change in prior, even though the true value of the marginal likelihood is about 100 times smaller.
There do exist circumstances in which the harmonic mean estimator actually works. For this model, if we set the prior standard deviation to s0=0.1, while keeping s1=1, we get a good estimate when the data is x=2 using only 1000 points:
> set.seed(1) > harmonic.mean.marg.lik(2,0.1,1,1000) [1] 0.05457312 > true.marg.lik(2,0.1,1) [1] 0.05479744
In general, we might expect the harmonic mean estimator to work adequately when the prior has much more influence on the posterior distribution than the data. This is hardly the typical situation, however, and when it does occur, the even simpler method of just averaging the likelihood over a sample from the prior distribution is likely to work better.
These plots show in more detail the behaviour on this example of the harmonic mean estimator, for a range of sample sizes, with ten estimates made for each sample size. Averaging the likelihood over the prior works better in both atypical situations where the harmonic mean estimator works adequately and in some situations where the harmonic mean estimator fails utterly. (Note, however, that sampling from the prior is not adequate for most real problems.)
My characterization of the harmonic mean of the likelihood as the Worst Monte Carlo Method Ever is based not just on its abysmal performance in most real problem, nor just on the fact that users of the method generally do not realize its poor performance, but also on the continued use of this method despite these flaws, due partly to wishful thinking on the part of its users, but also due to the connivance or negligence of many in the statistical community who ought to know better. The total unsuitability of the harmonic mean estimator should have been apparent within an hour of its discovery. In my contribution to the discussion of the paper by Newton and Raftery that introduced it, I pointed out (as I do above) that it can’t possibly work in the common situation where the posterior distribution is insensitive to the prior. Yet 13 years later, in 2007, this Bayesian Statistics 8 paper by Raftery, Newton, Satagopan, and Krivitsky still presents the harmonic mean estimator as a reasonable option, even while admitting that it doesn’t always work. Ten eminent statisticians contributed to the discussion of this paper, yet only the discussion jointly by Christian Robert and Nicolas Chopin appropriately warns of its “disastrous feature” of potential infinite variance that “may remain undetected”.
Raftery, et al. also state (in their reply to the discussants) that “our goal here is specific: a generic method for estimating the integrated likelihood of a model from posterior simulation output that uses only the loglikelihoods of the simulated parameter values”. It seems that 13 years was not enough time to absorb my argument that this goal is impossible to acheive.
Entry filed under: Monte Carlo Methods, Statistics, Statistics - Computing, Statistics - Technical.
38 Comments Add your own
Leave a comment
Trackback this post | Subscribe to the comments via RSS Feed

1. Andrew Gelman | 2008-08-18 at 4:33 pm
Radford,
Meng and Wong discuss this issue thoroughly in their paper on bridge sampling from 1996 or so.
2. radfordneal | 2008-08-18 at 5:06 pm
Andrew,
I assume you mean this paper from Statistica Sinica. Although they briefly mention the harmonic mean estimator, as a special case of the more general class that they investigate, I can’t see any assessment of its merits. In any case, I’m not trying to claim that I’m the only one to recognize how bad the harmonic mean estimator is. My goal is to publicize how horrible it is so that people will stop using it!
3. Andrew Gelman | 2008-08-19 at 6:51 am
Yeah, I’m with you on that. The bridge sampling paper is helpful in that (a) it gives some intuition about the problems with the harmonic mean formula, and (b) it gives the bridge sampling formula, which is easy to use and dominates the harmonic mean.
Mentioning the Meng and Wong paper takes you beyond a rant (which was great, and it got my attention) to something that people can use to do better.
4. Bill Jefferys | 2008-08-20 at 8:38 pm
I am astonished the people are still using this, when it has been so discredited for so long.
Thanks for the examples and the discussion, which are excellent!
5. Christian Robert | 2008-08-21 at 1:57 am
It is unfortunately worth repeating this warning as simple methods have a tendency to remain in use despite obvious shortcomings, just because they are simple…
In a related area, would you have any comment on the Nested Sampling approach of John Skilling, also presented at the last Valencia meeting? It has been adopted by many in Physics, in particular in Astronomy, but I feel it is less efficient than bridge sampling as a way to compute the marginal likelihood, being at least as slow as a naive slice sampler.
6. Bill Jefferys | 2008-08-22 at 7:27 pm
@Chris
In 2006, Jim Berger hosted a workshop on astrostatistics at SAMSI. Our group included Jim, Merlise Clyde, Tom Loredo and others. We were looking at a number of ideas on calculalting marginal likelihoods. We did look into Nested Sampling, but I think we were not particularly impressed with its performance. The variance of the estimates we were quite large, even for a pretty simple example.
Of course, this is in any case a notoriously difficult problem, and no approach is universally good. Many problems are quite intractable, especially multimodal ones (and in astronomy, searching for extrasolar planets by looking at wobbles in the star’s radial velocity is one such).
There is a paper and discussion that came out on our investigations, which are included in the proceedings volume for the conference “Statistical Challenges in Modern Astronomy, IV”, which includes the proceedings of the SAMSI workshops. Merlise is the lead author on the main paper.
Regards, Bill
7. Donald Lacombe | 2008-08-26 at 11:27 am
Professor Neal,
Any comment on the Chib (JASA, 1995) method of computing the marginal likelihood?
8. Radford Neal | 2008-08-26 at 8:51 pm
Chib’s method is certainly more generally useful than the harmonic mean of the likelihood!
In its simplest form, it estimates the posterior probability of some typical parameter value by averaging the probabilities of getting it by a Gibbs scan over a Gibbs sampling run. Comparing this estimate with the unnormalized probability (prior x likelihood) gives the normalizing constant, which is the marginal likelihood for the model.
This will work well if Gibbs sampling can move around most of the parameter space iin a few iterations, without being trapped in local modes. This probably includes some not-too-difficult problems that are of practical interest. For more difficult problems, one could try Chib’s extension in which multiple runs are used, but it’s not clear that this will always work well.
One must beware that for models with multiple equivalent modes (such as relabellings in a mixture model), the MCMC run must mix between such modes, even though this is unnecessary for most estimation tasks, like making predictions. This problem invalidates some examples in Chib’s paper, as I discuss here.
9. Computation of evidence « Xi’an’s Og | 2008-10-30 at 6:47 am
[…] though it may be prone to misbehaviour as it relates to harmonic mena (see Radford Neal’s point). (Interestingly [?], googling on that term leads to links to Ò Ruanaidh & Fitzgerald’s […]
10. Nicolas Lartillot | 2009-04-30 at 11:07 pm
Dear Radford,
I am happy to hear you say all that. And glad to see that this post is among the top 4 hits when searching google for ‘harmonic mean estimator’, because it means that you (we) are not preaching in the desert…
I am afraid that this HME has done more harm to bayesian studies than any opponent to bayesian inference has ever done.
Incidentally, the HME is also a striking example of how misleading the sample variance can be. When I try to convince people that the HME is not reliable, they usually seem very disturbed by the fact that this ‘infinite variance problem’ I seem to be so worried about does not show up when they compute the sample variance.
I then try to explain that the sample variance, as an estimator of the true variance, ALSO has an infinite variance, but then, it usually gets rather helpless: people just do not get the point, think that I see problems where they aren’t any, and opt for using the HME (which is anyway so much simpler than the never ending path sampling approaches that I try to sell them) ..
I don’t know if there is any better way to explain this true variance versus sample variance issue, do you know of any ?
in any case. thank you for this post
11. Radford Neal | 2009-04-30 at 11:59 pm
The possibility that the sample variance is far from the true variance is one that should be kept in mind in many contexts, such as time series with high autocorrelation. The Harmonic Mean Estimator is an extreme case, though. I don’t have any great ideas for convincing people of the problem. However, if they realize that the true variance may be infinite, but say it’s not a problem since the sample variance was finite, maybe one could ask them how one could possibly get an infinite sample variance….
12. Nicolas Lartillot | 2009-05-01 at 10:36 am
Radford,
thanks for your response
actually, the cases I am interested in are such that the variance of the HME is not truly infinite (the likelihood does not vanish at infinity) although it is practically immensely large (~ V > 10^100). Therefore, in principle, the sample variance IS well behaved estimator of this large V, and people do expect to see the sample variance give them some warning about the fact that V is large.
Of course, the sample variance will correctly estimate V only once the number of independent points in the sample is of the order of the square of V.
But what this means in practice is that the sample variance is not a good estimator of the order of magnitude of the true variance. It is just a good estimator of the variance once you know the order of magnitude, and have adjusted your sample size accordingly.
It may be something obvious, but I guess many people are not aware of that (or else, they would not rely exclusively on the sample variance to feel confident about an estimator, as they often do).
13. Harmonic mean estimators « Xi'an's Og | 2009-07-30 at 6:09 am
[…] support is one of those regions. This cancels the infinite variance difficulty rightly stressed recently by Radford Neal. In short, the fact […]
14. Quadrature methods for evidence approximation « Xi'an's Og | 2009-11-13 at 1:43 am
[…] John Skilling does not justify nested sampling that way but Martin Weinberg also shows that the (infamous) harmonic mean estimator also is a Lebesgue-quadrature approximation. The solution proposed in the […]
15. Alternative evidence estimation in phylogenetics « Xi'an's Og | 2010-01-20 at 6:04 pm
[…] Series B) is still the one used in phylogenetic softwares like MrBayes, PHASE and BEAST, despite clear warnings about its unreliability! In An alternative marginal likelihood estimator for phylogenetic models, […]
16. saverio vicario | 2010-02-03 at 7:32 am
Thanks for the very clear post, but I am searching a reference in a pubblished paper that report those points.
I am biologist and I would like to point out the advantage of Savage Dickey ratio versus the harmonic mean in a phylogographic approach. I have not the background to report fully the discussion of this post and I would like to report a citation in a peer reviewed journal that make the point that the harmonic mean is not a well behaved estimator.
In your post two refernces are cited (Statistica Sinica 6(1996), 831-860) and your discussion. Unfortunately the first article is not very clear in making the point (as you an gelman are point out) and the second one is not peer reviewed.
17. Another harmonic mean approximation « Xi'an's Og | 2010-06-26 at 6:10 pm
[…] small values of” the likelihood, while, as clearly spelled out by Radford Neal, the poor behaviour of the harmonic mean estimator has nothing abnormal and is on the opposite easily […]
18. Ben | 2010-09-15 at 11:05 am
Wow, I was just reading about ways to compute Bayes Factors and was about to implement the HME approximation when I found this. Thanks, internet!
19. Ben | 2010-09-16 at 12:45 am
I’m just trying to compare two models via Bayes factors. I’ve done a bit of reading on this, but there are tons of different options on how to compute them. I’d like something that doesn’t require much thinking or intelligence on my part.
I think even the original Raftery mentions the option of using importance sampling on a mixture of the prior and posterior distributions. If you use importance sampling on the posterior, you get the harmonic estimator which I know now is pretty worthless. But what about using a 50/50 mix of the prior and posterior distributions as the weighing function? That still seems pretty easy to do for an arbitrary model. Will that get me the right answer? Is there a better way that is equally simple?
I don’t work in academia—I just made some simple models in JAGS for work and now I want to see which is better. It seems all of this should be simpler than its turning out to be.
Thanks for any advice!
20. Bayesian model selection « Xi'an's Og | 2010-12-08 at 2:37 am
[…] 6 introduces the worst possible choice for the Gelfand-Day’s (sic!) estimator by considering the harmonic mean version with the sole warning that it “can be unstable in some applications” (page […]
21. David | 2011-07-13 at 12:48 am
I’d love to see a followup post on this particular issue — estimating the marginalized posterior for Bayes factor calculation — using some other aspect of MCMC.
22. Bayesian ideas and data analysis « Xi'an's Og | 2011-10-30 at 7:15 pm
[…] which indeed amount to using the dreadful harmonic mean estimate!!! They apparently missed Radford’s blog on the issue. (Chapter 4 is actually the central chapter of the book in my opinion and I could make […]
23. Martha K. Smith | 2011-11-30 at 12:21 am
Thanks for the post. I just encountered the harmonic mean of sampled likelihoods as an estimate of the marginal mean in Testing Spatiotemporal Hypothesis of Bacterial Evolution Using Methicillin-Resistant Staphylococcus aureus ST239 Genome-wide Data within a Bayesian Framework, Gray et al, Mol. Biol. Evol. 28(5):1593-1603, online November 26 2010. I wondered why/if the harmonic mean was appropriate — and quickly found this page.
24. Kevin S. Van Horn | 2011-12-20 at 1:30 pm
Very useful post; thank you for publicizing this problem. (BTW, I’ve been a fan of your work ever since reading your doctoral dissertation in the mid 90’s.)
My only possible point of disagreement is this:
“Use of the marginal likelihood to evaluate models is often rather dubious, because it is very sensitive to any flaws in the specifications of the priors for the parameters of each model.”
I agree that using the marginal likelihood appropriately is difficult, both computationally and in dealing with priors. But the sensitivity to priors is not a bug; it’s a feature. If one’s intuition says that priors shouldn’t matter in model comparison, but the mathematics of probability theory says otherwise, it’s the intuition that needs to be fixed. I like to summarize this in the following couplet that parodies a well-known children’s song:
Priors matter; this I know.
The mathematics tells me so.
:-)
(Yes, as a pragmatist I realize that the difficulties of using the marginal likelihood appropriately can be a legitimate reason to fall back on theoretically questionable but reasonably useful and easily applied alternatives.)
25. terrance savitsky | 2012-01-28 at 9:00 pm
… but estimation of the posterior predictive density under a leave-one-out estimation (e.g. the CPO = p(y_i|y_[-i]) is not the same as estimation of the marginal density because the former does depend on the posterior, so there is no issue that arises from a large distance between the posterior and prior, right? I do recognize the possibility for numerical instability from employing the reciprocal of the likelihood under outlying points may disable a law of large numbers result. still, it seems that Dr. Neal’s blog results in we practitioners conflating CPO estimation with that of the marginal density. The weighted re-sampling scheme that allows direct CPO estimation also may suffer from numerical instability because the weights employ the reciprocal of likelihoods. then it seems, in the absence of a test set, we must employ K-fold cross-validation.
26. Zane Zhang | 2012-03-08 at 5:18 pm
Dear Prof. Neal,
I am a practitioner. I do realize the problems associated with the Harmonic Mean estimator, and try, instead, to use reciprocal importance estimator : 1/(posterior mean of wlike), and wlike is calculated as: g(theta)/f(y)/f(theta), where g(theta) is the likelihood according to the importance density function similar to the posterior density, f(y) is the likelihood of the data, and f(theta) is the prior likelihood, at each MCMC iteration.
I have one question about this calculation. It appears that different settings of the prior distributions would have a considerable effect on the calculated outcome. For a simple instance, say we have two models:
y ~ dnorm(b*x, tau)
y ~ dnorm(a + b*x, tau)
and we are to assess which model performs better. We set non-informative normal prior (dnorm(mean, precision)) for b and a: b~dnorm(0, 0.0001) and a~dnorm(0, 0.0001), construct the importance density functions according to posterior estimates of the parameter values, and then calculate the difference between the estimated marginal likelihoods for the two models using the reciprocal importance sampling estimator. This difference is apparently related to the setting of the prior for a (assuming the posterior distribution is not sensitive to what the prior is.). If the prior setting for a is changed to: a ~ dnorm(0, 0.000001), the difference will change correspondingly, although parameter estimates remain practically the same (assuming both prior settings are sufficiently non-informative).
My question is if prior settings are non-informative, will it be OK to leave the priors out in the calculation? If not, how we may overcome this problem apparent to me. I would be really grateful, if Prof. Neal and/or any other Statisticians would provide helps.
27. Radford Neal | 2012-03-08 at 6:54 pm
There are some terminological issues with your comment here, which may impede understanding (including by me). You seem to be using “likelihood” as a synonym for “probability”, but it isn’t. The likelihood is the probability of the observed data, seen as a function of the model parameters that determine that probability, except that factors that don’t depend on these parameters may be ignored. It isn’t anything other than that. Also, R’s dnorm function takes the mean and standard deviation as arguments, not the precision.
Trying to get past these terminological issues, I’m still not sure what method you’re using. When you write g(theta)/f(y)/f(theta), do you really mean g(theta)/(f(theta)f(y|theta))? Are you sampling from g or from the posterior? It seems like you must be sampling from the posterior, since otherwise this wouldn’t make any sense, in which case g should some distribution that has significant probability only in places where the posterior probability is significant, but isn’t too concentrated compared to the posterior. For the most difficult problems, finding such a g is hard. But maybe you can for your problems.
Supposing you’ve got a good estimate, the behaviour you describe in which the marginal likelihood changes when you change the prior is exactly what is expected. You generally can’t use non-informative priors when comparing models by marginal likelihood, except perhaps for parameters that exist in all the models, and play the same role in all of them, for which the effects of a non-informative prior will cancel. As I say near the beginning of this post, using marginal likelihood to compare models is attractive in theory, but difficult in practice. Also, you probably don’t want to compare models anyway, but would be better off to instead introduce hyperparameters that continuously vary whatever varies from one model to another.
28. Zane Zhang | 2012-03-08 at 8:02 pm
Thanks so much, Prof. Neal, for your prompt reply, and sorry for the terminlogical problems. I was attempting to use reciprocal importance sampling estimator (Gelfand and Dey, 1994) to estimate marginal likelihood for model comaprison. I was using WinBugs rather than R, and therefore expressed the dnorm function in terms of the mean and precision. I estimated the marginal likelihood in the following procedures:
1) Get posterior MCMC samples for model parameters,
2) Formulate the density function, g, using a multivariate normal with mean and variance-covariance according to the posterior MCMC samples,
3) Rerun the model, calculating the log density (g(theta)) based on the density function g, log likelihood (f(y)), and log prior density (f(theta)) for a given set of parameter values at each iteration,
4) Calculate wlike as exp[g(theta) – f(y) – f(theta)]
5) When the Run ends, estimate the marginal likelihood as 1/(posterior mean of wlike).
Not so sure if I was doing the right thing. I would be very grateful, if you could please comment again, pointing out the problems.
It is good, despite some disappointment, to know that “You generally can’t use non-informative priors when comparing models by marginal likelihood, except perhaps for parameters that exist in all the models, and play the same role in all of them, for which the effects of a non-informative prior will cancel.”
In any sense, thanks again, Prof. Neal. I learned quite a deal from your reply.
29. Radford Neal | 2012-03-08 at 8:34 pm
That sounds about right, on a brief glance, except that I don’t think setting g to a normal distribution with mean and covariance matching the posterior is going to work, in general, since it will likely give substantial probability to points that have negligible probability in the posterior (unless the posterior is actually normal). I think the estimator you’re using will then give the wrong answer, for approximately same reason that the harmonic mean estimator doesn’t work well.
30. Zane Zhang | 2012-03-09 at 12:35 pm
Setting g to a normal distribution may not be appropriate for my models. However, the bigger problem, as least it seems to me, is the influence of the magnitude of the prior variance on the marginal likelihood. Non-informative priors were used for my models, and one model contains one or two additional parameters relative to the other model to be compared with. Setting different prior precisions for these parameters would change the marginal likelihood, resulting in different estimates of the Bayes factor. That is really annoying!
31. Radford Neal | 2012-03-09 at 1:01 pm
Marginal likelihoods are supposed to be sensitive to the prior distribution used. I think the problem is that you don’t actually want to compare models by marginal likelihood / Bayes factors.
32. Zane Zhang | 2012-03-09 at 1:18 pm
You are right, Prof. Neal. Appreciate your grateful help, indeed!
33. Peter | 2012-03-26 at 5:36 pm
I would have thought a better approach is to sample from whichever distribution is sharper, the prior or the likelihood, and then take the average over the rest. E.g. for binomial, the likelihood (x|np) function is a product of binomials, but this is the same as a product of beta distributions. So you could sample from the beta(x+1,n-x+1) distributions, then average the prior density at each sample. If the prior is informative, then you sample the prior, and evaluate the likelihood. This ensures that you stay in the “high integrand” region. I also like the “high likelihood” region version where P(x)=P(x|t-max) x int P(x|t)/P(x|t-max)*P(t) dt. Takes the intuitive form of “log(evidence)” = “maximised log-likelihood” – “penalty”. However these are outside the realm of MCMC…..
34. Radford Neal | 2012-03-26 at 7:47 pm
The likelihood isn’t a distribution, but I assume you mean to sample from a distribution whose density is proportional to the likelihood. It’s possible that there is no such distribution (the likelihood can integrate to infinity), but let’s suppose there is.
I think this won’t work in general, since you generally don’t know the normalizing constant needed to turn the likelihood into a density function. The goal is to find the integral of the prior times the likelihood over the parameter space. If you estimate this by sampling proportionally to the likelihood, you need to average the prior times the normalizing constant for the likeihood. So you haven’t really reduced to an easier problem, in most cases.
35. Greg | 2013-04-18 at 7:35 pm
Dear Prof. Neal,
Thank you so much for this post, I’ve found it really useful. I’m about to implement some method to calculate the marginal likelihood of an econometric model and now I see that the harmonic mean estimator is not an attractive solution. What do you think about Geweke’s (1999) modified harmonic mean estimator (p.46 here: http://www.tandfonline.com/doi/pdf/10.1080/07474939908800428)?
Thank you for your help in advance!
Best,
Greg
36. Marginal likelihood from tempered Bayesian posteriors | Darren Wilkinson's research blog | 2013-10-01 at 9:06 am
[…] evidence. This leads to the harmonic mean estimator of the evidence, which has been described as the worst Monte Carlo method ever! Now it turns out that there are many different ways one can construct estimators of the evidence […]
37. Generating Random Numbers From a Specific Distribution With The Metropolis Algorithm (MCMC) « The blog at the bottom of the sea | 2019-05-25 at 11:19 pm
[…] There is something called the “Harmonic Mean Estimator” that does this, but has infinite variance so is called “The Worst Monte Carlo Method Ever”. https://radfordneal.wordpress.com/2008/08/17/the-harmonic-mean-of-the-likelihood-worst-monte-carlo-m… […]
38. Longhai Li | 2020-03-05 at 10:42 pm
I am thinking whether the harmonic mean or a modified version may be interpreted as another quantity other than marginalized likelihood. A value that is not sensitive to the prior is indeed what we want for comparing models. For example, when y_i are independent, the harmonic mean of each f(y_i|t) is the cross-validatory predictive density f(y_i|y_{-i}). Perhaps harmonic mean of the joint density or something else is something else of interest.